How To Crawl a Website
There are two options to start a crawling of a website:
-
Crawl Now
-
Schedule Crawling
Crawl Now
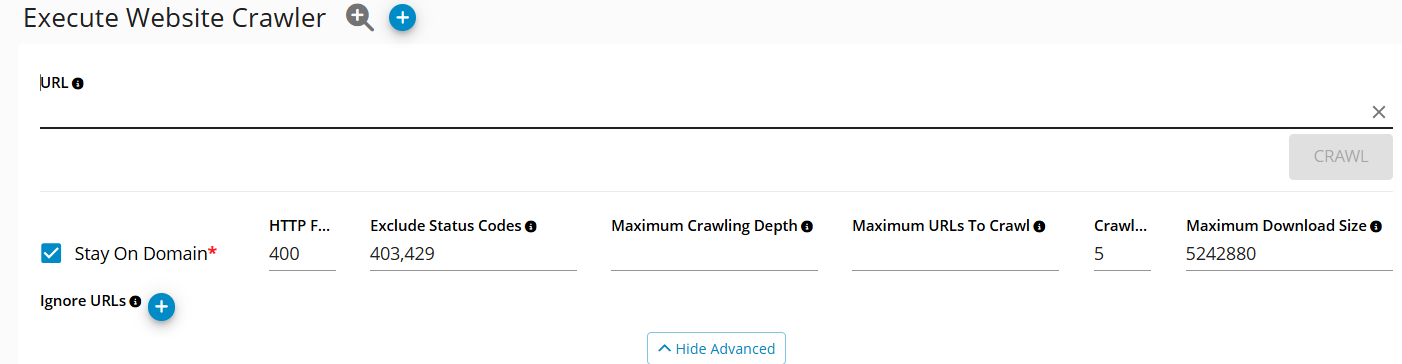
This is the quickest way to execute a website crawler and get its results once completed. Configuration settings in this option are limited but sufficient for most use cases.
Go to Germain Workspace > Left Menu > Analytics > Website Crawler > enter URL
Schedule Crawling
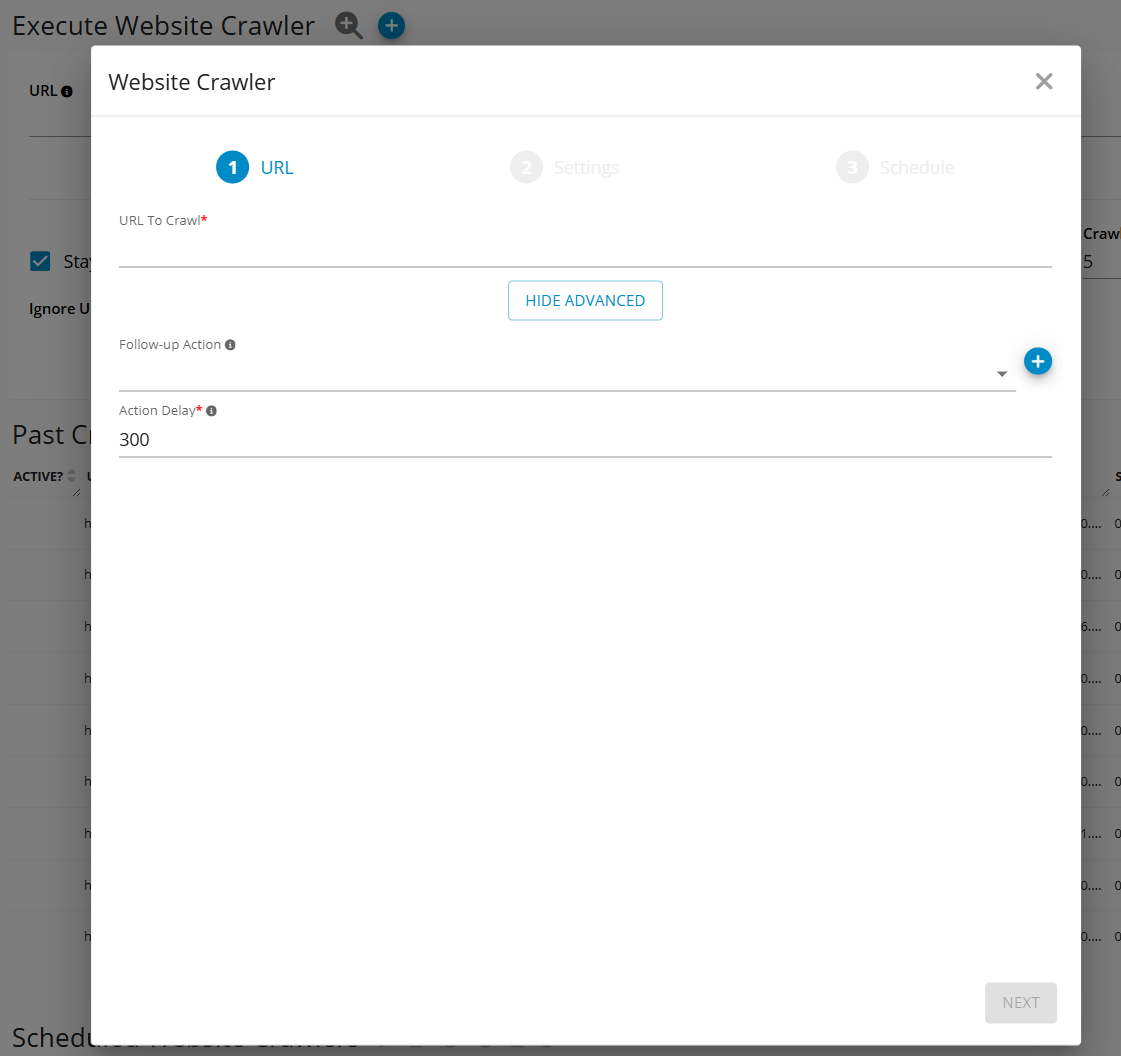
This is a more advanced option and it allows to configure:
-
A website crawler on a schedule
-
Provide more advanced settings to the crawler (e.g. customer headers, authentication settings, connection settings and more)
Go to Germain Workspace > Left Menu > Analytics > Website Crawler > Click + (blue icon)
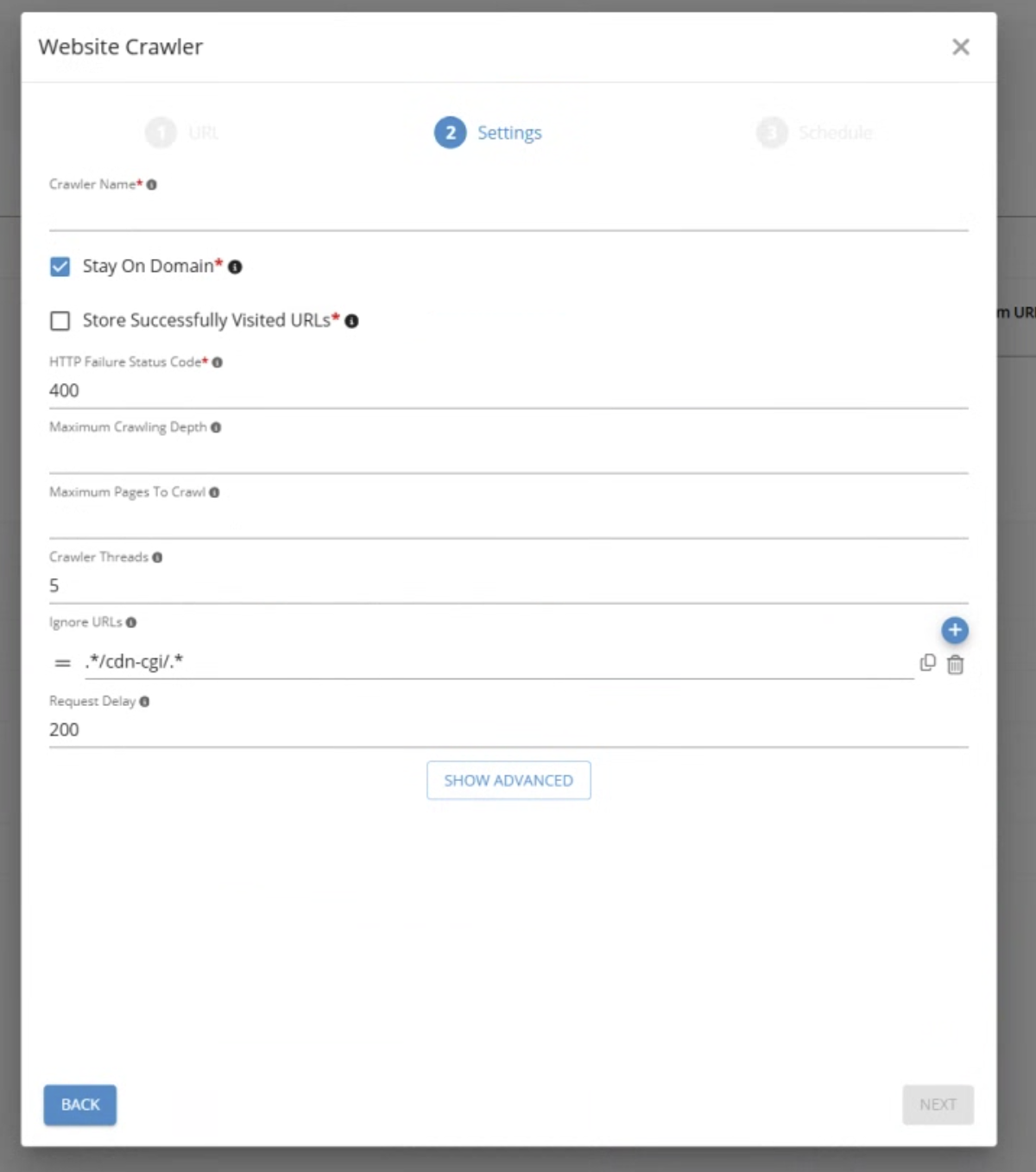
Settings
-
URL: Starting URL for the crawler.
-
Stay On Domain
-
True: Visit only URLs on the same domain or its subdomain (e.g. http://google.com and drive.google.com are on the same domain)
-
False: Visit every URL
-
-
Store Successfully Visited URLs
-
True: Store all Website URL Availability facts (these representing available and not available URLs)
-
False: Store only failed Website URL Availability facts (not available URLs only)
-
-
HTTP Failure Status Code: Any visited URL with returned HTTP status code equal or bigger to this value will be considered as unavailable.
-
Maximum Crawling Depth: This value represents how deep the crawler can visit URLs. Null value means no cap for maximum crawling depth.
-
Maximum URLs To Crawl: This value puts a cap on how many URLs can be visited by the crawler. Null value means there is no cap for maximum URLs to crawl.
-
Crawler Threads: How many independent threads will be used to crawl your website. More threads means more resources needed but quicker execution time.
-
Ignore URLs: URLs which shouldn’t be ignored by the crawler. Regex patterns are allowed if you want to exclude all domains (e.g. to ignore all URLs from drive.google.com, you need to add .*drive.google.com.* value)
-
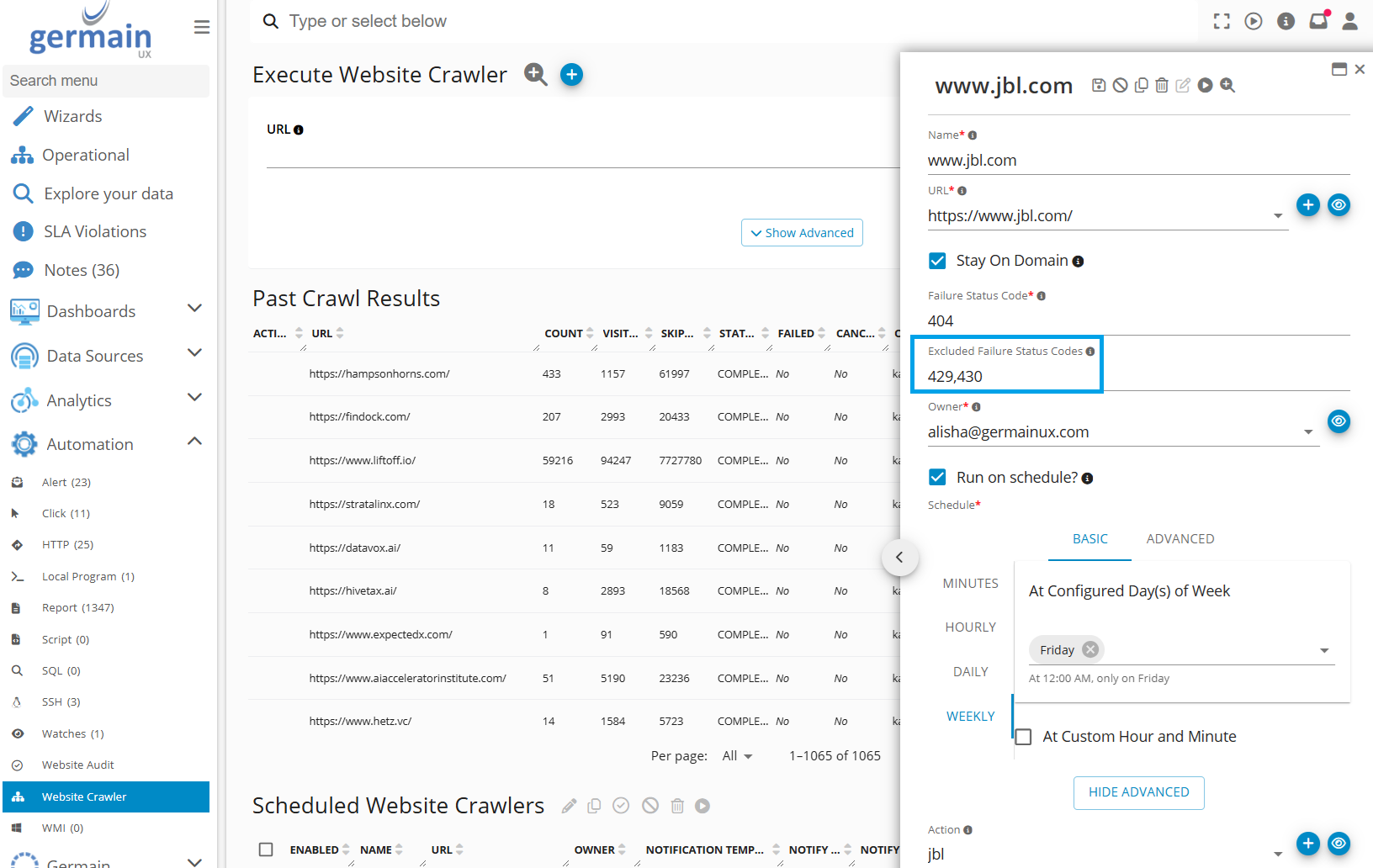
Excluded Failure Status Code: Exclude any status code (e.g., 404, 503, etc.) so GermainUX only flags failures or statuses that are meaningful to your organization.
-
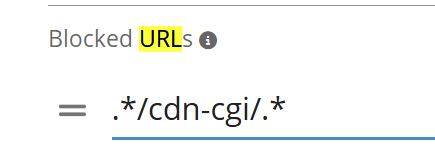
Blocked URLs: Exclude specific URLs—useful for ignoring known or irrelevant pages, or avoiding false positives caused by services like Cloudflare. Example: Exclude 404 errors from Cloudflare-hosted pages that are not actual issues. This prevents unnecessary noise in your reports and keeps the focus on real problems.
-
Many other parameters are available.
Please contact us whenever needed.
Service: Automation
Feature Availability: 2024.1