This new Correlation Engine is another great step forward to have Germain provide smarter insights (in the past, Germain used to correlate some data, but none of that correlation was configurable).
-
Any data, that Germain collects, can be correlated to one another.
-
Correlation is configurable via config console
-
One or many properties (id, name, etc) can be used for correlation
Configuration
This new correlation engine is preconfigured to analyze the root-cause of a Siebel Object Manager crash, so we will be using that as our use case to show you and it can be configured.
-
Open up Germain Configuration Console and go to germain.apm.analytics.correlationScenarios
-
Create a new correlation scenario:
Name – value to be used to configure a KPI to show the correlated data
Retention – how long to keep the correlated data in cache. In this case, we expect all raw crash data to be received within 1 hour
Fact class – model type to store correlated data in
Name Generator – MVEL expression that will populate the “name” field on the correlated data point

-
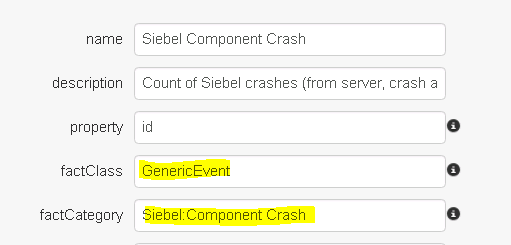
Select the KPIs that will contain the raw data to correlate.
In this example, there are 3 Siebel crash data types that are collected by Germain. Any data point that matches either of the KPIs will be included by the correlation service as part of this scenario

-
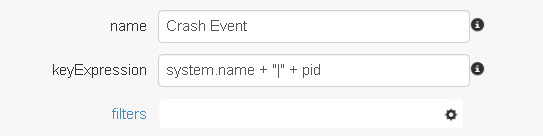
Configure how incoming KPIs / raw data are correlated.
Name – an identifier to uniquely identify this type
Key Expression – an MVEL expression that will generate a key for this correlation scenario from a raw data point. In this example, the key is comprised of server name and process ID, but other values are possible as well (ex: session ID). Any raw facts that share the same key value will be correlated.
Filters – Specifies filters on the raw data, if any. This makes it possible to assign raw data to a specific correlation type.
In this example of a Siebel Crash, we will only define a single type for this purpose:
-
Example of Filters

-
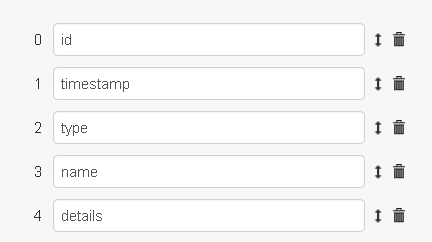
Define which fields to exclude from correlation for the “Crash Event” type. Any fields not included on this list will be copied from the raw data to the correlated fact. For example, since system.name is not included in the list, the correlated fact’s system.name will match the raw facts’ system names.
Once the correlation scenario has been created, the system will begin processing incoming raw data.
-
In order to visualize the correlated data on a dashboard, create a new KPI that matches the Fact Class and Name properties of the scenario: